*dest=IDENT; for(i=0;i<length;i++){ data_t val; get_vec_element(v,i,&val); *dest=*dest OP data[i]; } }
使用临时变量替代传入的指针变量(临时变量方便寄存器优化而不是内存地址读取数据)
1 2 3 4 5 6 7 8 9 10 11
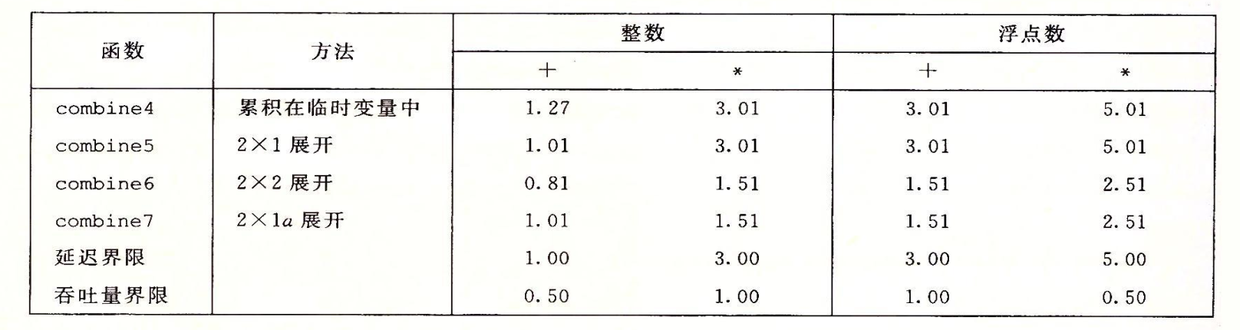
void combine4(vec_ptr v,data_t *dest){ long i; long length = vec_length(v); data_t *data=get_vec_start(v); data_t acc=IDENT;
for(i=0;i<length;i++){ acc=acc OP data[i]; } *dest=acc; }
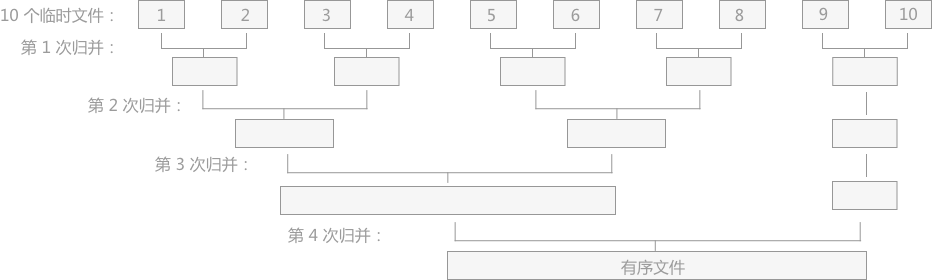
k*n循环展开
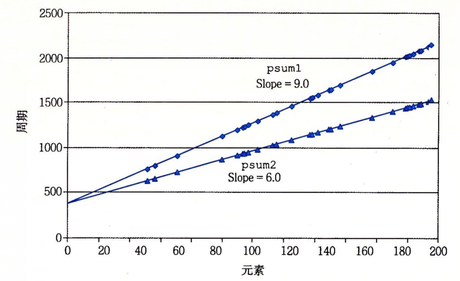
步长为二,一个循环(21)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
void combine5(vec_ptr v,data_t *dest){ long i; long length = vec_length(v); long limit = length-1; data_t *data=get_vec_start(v); data_t acc=IDENT; // combine 2 elements at a time for(i=0;i<limit;i+=2){ acc=(acc OP data[i])OP data[i+1]; } // Finish any remaining elements for(;i<length;i++){ acc = acc OP data[i]; } *dest=acc; }
步长为二,两个循环(22)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
void combine6(vec_ptr v,data_t *dest){ long i; long length = vec_length(v); long limit = length-1; data_t *data=get_vec_start(v); data_t acc0=IDENT; data_t acc1=IDENT; // combine 2 elements at a time for(i=0;i<limit;i+=2){ acc0=(acc0 OP data[i]); acc1=(acc1 OP data[i+1]); } // Finish any remaining elements for(;i<length;i++){ acc0 = acc0 OP data[i]; } *dest=acc0 OP acc1; }
重新结合变换(k*1a)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
void combine7(vec_ptr v,data_t *dest){ long i; long length = vec_length(v); long limit = length-1; data_t *data=get_vec_start(v); data_t acc=IDENT; // combine 2 elements at a time for(i=0;i<limit;i+=2){ acc=acc OP (data[i] OP data[i+1]); } // Finish any remaining elements for(;i<length;i++){ acc = acc OP data[i]; } *dest=acc; }
class BaseParameters { public: virtual void reset() {} }; class MyParameters : public BaseParameters { public: int data[3]; int buf[3]; }; MyParameters my_pars; memset(&my_pars, 0, sizeof(my_pars)); BaseParameters* pars = &my_pars; //..... MyParameters* my = dynamic_cast<MyParameters*>(pars);
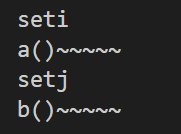
#include <iostream> using namespace std; int seti() {cout << "seti" << endl;return 1;} int setj() {cout << "setj" << endl;return 1;} class a { public: a() {cout << "a()~~~~~" << endl;} }; class b { public: b():j(setj()),i(seti()) {cout << "b()~~~~~" << endl;} int i; a ca; int j; }; int main() { b ob; return 0; }
构造函数执行顺序:public里面 int i 先声明,就先构造 i,然后类a ca 声明,再构造 ca,然后声明 j,就构造 j,最后执行 b() 构造函数里面的东西。
另外举个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
#include <iostream> using namespace std; class A { private: int n1; int n2; public: A():n2(0),n1(n2+2){} void Print(){ cout << "n1:" << n1 << ", n2: " << n2 <<endl; } }; int main() { A a; a.Print(); return 1; }