Kafka 单机吞吐量可达百万级 TPS,适用场景包括日志采集、实时计算和大数据管道。例如,社交平台的实时动态流或物联网设备数据采集。Kafka 不适合需要复杂路由或事务一致性的场景。
RocketMQ 单机吞吐量可达十万级 TPS
RabbitMQ 的单机吞吐通常在每秒数千条
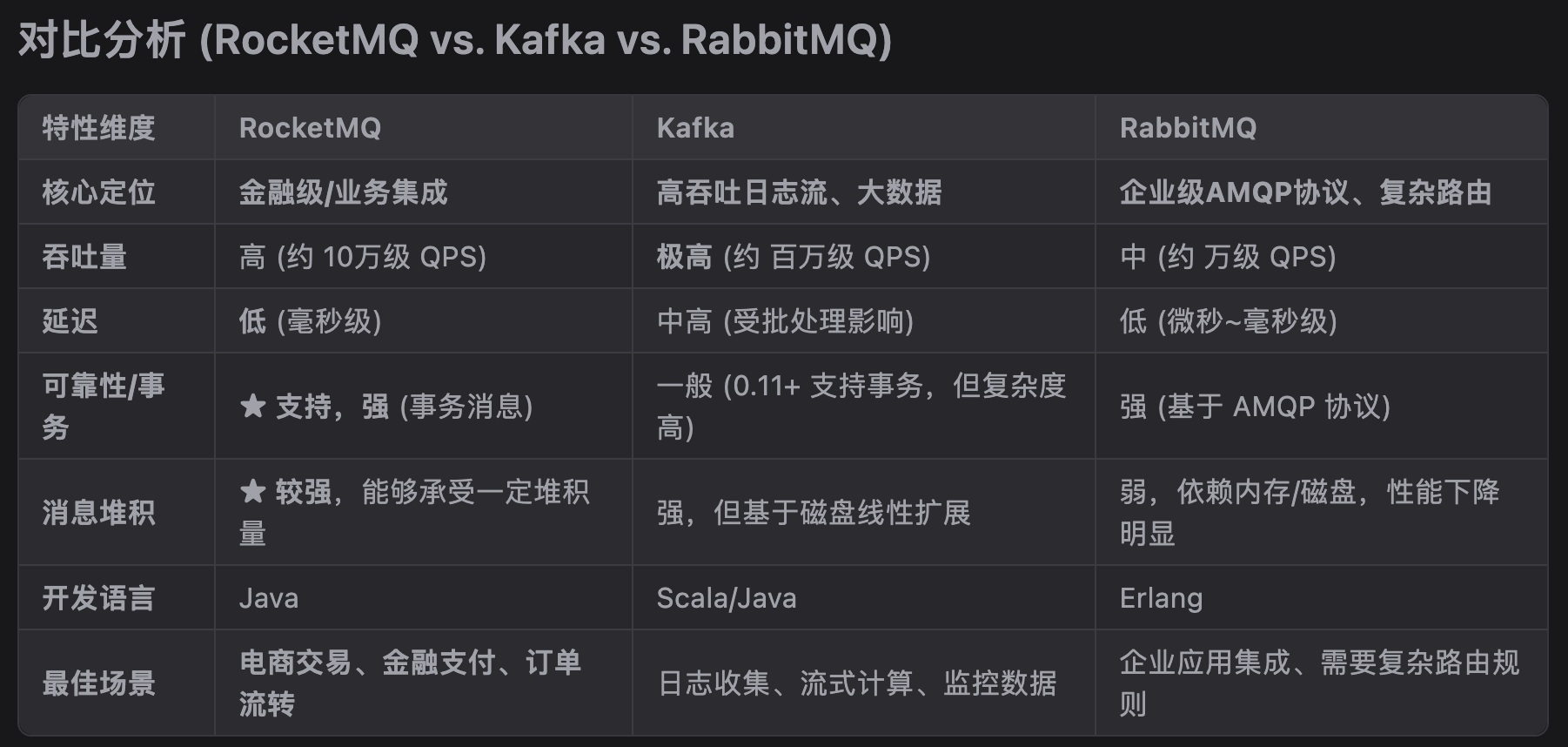
RocketMQ(金融级)
RocketMQ 的消费者默认采用了一种模拟推(Push)的、基于长轮询的拉(Pull)模型。
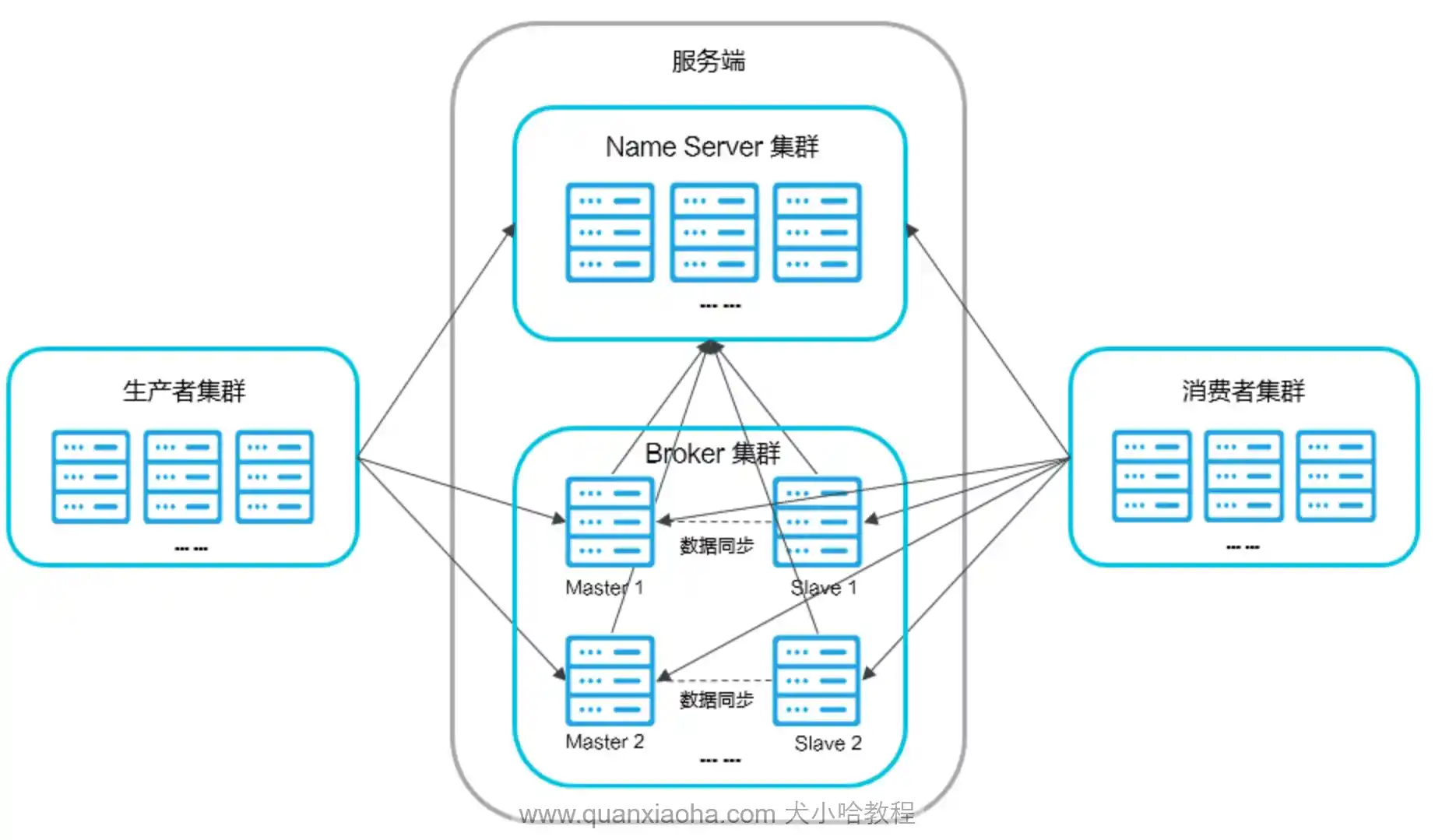
分布式事务消息:这是 RocketMQ 的王牌功能。它通过 “半消息 (Half Message)” 和 “消息回查” 机制,实现了类似 XA 的分布式事务最终一致性,是解决跨系统事务的一种方案。
整个流程分为两个阶段:
第一阶段 - 发送半消息【生产者 -> send msg -> broker】:生产者发送一个对消费者不可见的 “半消息” 到 Broker。Broker 持久化该消息,但不会将其投递到目标 Topic。
第二阶段 - 提交或回滚【生产者 -> send commit -> broker】:生产者执行本地事务,并根据执行结果(成功/失败)向 Broker 发送一个 Commit 或 Rollback 指令。Broker 根据指令,将半消息变为正常消息投递给消费者,或直接将其丢弃。
【broker -> 回查 -> 生产者】为了处理生产者宕机或网络异常导致第二阶段指令无法发送的 “悬而未决” 状态,RocketMQ 引入了事务状态回查机制,由 Broker 主动向生产者查询本地事务的最终状态。
- RocketMQ 事务消息将消息表 “外置” 到了消息中间件中,简化了业务方的开发复杂度,避免了重复造轮子,性能和可靠性更高。
与 2PC 对比:它是弱化的 2PC,不保证强一致性(因为存在回查延迟),但通过异步和重试机制,实现了高可用和最终一致性,更适合互联网场景。
与 TCC 对比:事务消息专注于解决异步消息场景的一致性;TCC 则适用于需要明确预留、确认/取消多个服务资源的同步或异步场景,粒度更细,但实现也更复杂。
RocketMQ 通过 “分区有序” 模型来保证消息的顺序性。其核心是 “同一组顺序消息发送到同一个队列,且由一个消费者线程串行处理”。
有死信队列,有主备
RabbitMQ
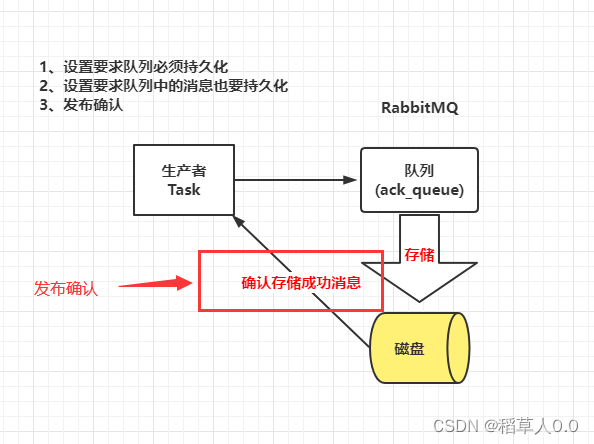
消息的强一致性保证机制
发送方
批量发送 N 条消息后一次性确认,发布确认(Confirm)模式最大的好处在于他是异步的,一旦发布一条消息,生产者应用程序就可以在等信道返回确认的同时继续发送下一条消息,当消息最终得到确认之后,生产者应用便可以通过回调方法来处理该确认消息。
Broker 侧
确保消息落地不丢失
队列持久化:声明队列时指定 durable=true,队列元数据会持久化到磁盘,Broker 重启后队列不丢失;
消息持久化:发送消息时指定 deliveryMode=2(持久化),消息会被写入磁盘(先写内存缓存,再异步刷盘),Broker 重启后消息不丢失;
镜像队列(Mirror Queue):开启队列镜像,将队列副本同步到集群多个节点,主节点故障时从节点接管,避免单点丢失;
消费者
确保消息被正确消费
手动确认(Ack):关闭自动确认(autoAck=false),消费者处理完业务逻辑后,主动调用 channel.basicAck() 确认消息;若处理失败,调用 basicNack()/basicReject() 让消息重新入队或进入死信队列;
幂等消费:通过消息唯一 ID(如 correlationId)+ 数据库唯一索引 / 分布式锁,避免消息重复消费导致的业务异常;
限流机制:通过 channel.basicQos() 设置每次预取的消息数(如 basicQos(10)),避免消费者过载导致消息堆积 / 丢失。
其他特性
RabbitMQ从3.6.0版本开始引入了惰性队列(Lazy Queue)的概念。 惰性队列会尽可能的将消息存入磁盘中,而在消费者消费到相应的消息时才会被加载到内存中,它的一个重要的设计目标是能够支持更长的队列,即支持更多的消息存储。 当消费者由于各种各样的原因(比如消费者下线、宕机亦或者是由于维护而关闭等)而致使长时间内不能消费消息造成堆积时,惰性队列就很有必要了
队列是消费者的 “数据源”:消费者必须明确绑定到某个 / 某些队列(通过 basic.consume 命令),才能接收该队列的消息;未绑定队列的消费者无法获取任何消息。
一个队列可被多个消费者绑定(一对多):这是最常见的场景,用于消息的负载均衡。
一个消费者可绑定多个队列(多对一):通过多次执行绑定命令,消费者可同时监听多个队列的消息(但实际开发中更推荐用交换机路由,而非直接绑定多队列)