在优化之前要提醒的内容:
1.任何级别的优化都将带来代码结构的改变。例如:对分支的合并和消除,对公用子表达式的消除,对循环内load/store操作的替换和更改等,都将会使目标代码的执行顺序变得面目全非,导致调试信息严重不足。
2.内存操作顺序改变所带来的问题:在O2优化后,编译器会对影响内存操作的执行顺序。例如:-fschedule-insns允许数据处理时先完成其他的指令;-fforce-mem有可能导致内存与寄存器之间的数据产生类似脏数据的不一致等。对于某些依赖内存操作顺序而进行的逻辑,需要做严格的处理后才能进行优化。例如,采用volatile关键字限制变量的操作方式,或者利用barrier迫使cpu严格按照指令序执行的。
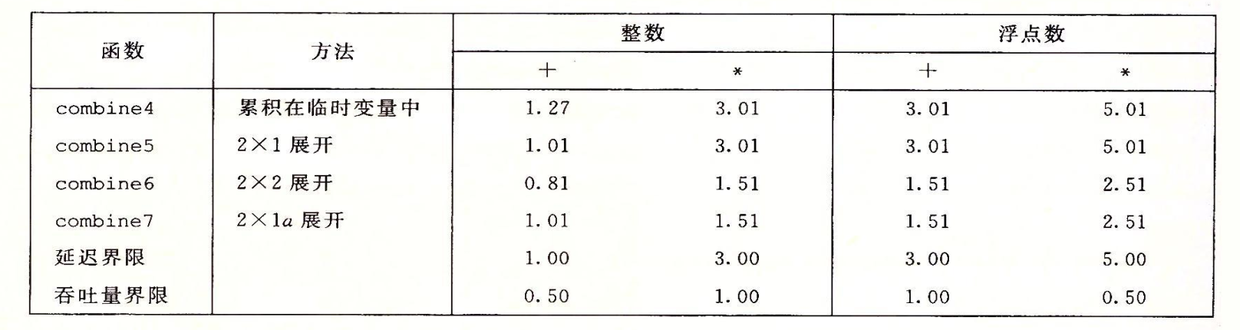
表示程序性能的标准:CPE(越小性能越优)延迟界限 吞吐量界限
CPE指数只是针对循环代码而言的(几乎可以说代码性能优化就是对循环的优化),它指处理数据的每个元素所消耗的周期数。之所以使用每个元素的周期数而不是每个循环的周期数来度量,是因为循环次数可能随循环展开的程度不同而变化。
延迟界限:当一系列操作必须按照严格的顺序执行时,处理每个元素所历经的关键路径(最长路径)的周期数。当数据相关问题限制了指令级并行的能力时,延迟界限能够限制程序性能。
吞吐量界限:处理器功能单元全力运行时的原始计算能力。比如处理器具有两个能同时做乘法的单元,对于只有1次乘/元素的循环而言,此时的吞吐量界限就是0.5。吞吐量界限是程序性能的终极界限。
程序转换的优化安全:
- 内存别名使用:如果
1
2
3
4
5
6
7void twiddle1(long*xp,long*yp){
*xp+=*yp;
*xp+=*yp
}
void twiddle2(long*xp,long*yp){
*xp+=2* *yp
}*xp=*yp,则twiddle1会是增加四倍(xp翻倍的同时yp也翻倍),twidde2则是增加三倍,编译器不知道xp会不会等于yp,所以无法将代码从twiddle1优化为twiddle2
2.函数调用合并1
2
3
4
5
6
7
8
9
10
11
12long counter=0;
long f(){
return counter++;
}
long func1(){
return f()+f()+f()+f();
}
long func2(){
return 4*f();
}
func1的结果是0+1+2+3=6,而func2的结果是4*0=0
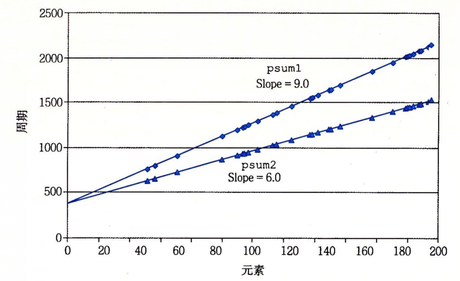
循环展开技术(-O3)
一种牺牲程序的尺寸来加快程序的执行速度的优化方法。可以由程序员完成,也可由编译器自动优化完成。循环展开最常用来降低循环开销,为具有多个功能单元的处理器提供指令级并行。也有利于指令流水线的调度。
1 | // 计算p[i]=a[0]+...a[i] |
gcc 参数优化
-Og 使用基本的优化
-O1 … -O3 使用更大量的优化,但是也可能增加程序的规模(主要以O1为主)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 通过修改data_t修改数据类型
#define data_t int
// 通过修改OP来修改执行的是加还是乘
#define IDENT 0
#define OP +
void combine1(vec_ptr v,data_t *dest){
long i;
*dest=IDENT;
for(i=0;i<vec_length(v);i++){
data_t val;
get_vec_element(v,i,&val);
*dest=*dest OP val;
}
}

频繁使用数据缓存(针对全局变量和数组保存中间结果)
1 | // combine1 |

减少过程调用
把函数调用取消直接访问元素,性能没啥提升。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16data_t* get_vec_start(vec_ptr v){
return v->data;
}
// combine3
void combine3(vec_ptr v,data_t *dest){
long i;
long length = get_vec_element(v,i,&val);
data_t *data = get_vec_start(v);
*dest=IDENT;
for(i=0;i<length;i++){
data_t val;
get_vec_element(v,i,&val);
*dest=*dest OP data[i];
}
}

使用临时变量替代传入的指针变量(临时变量方便寄存器优化而不是内存地址读取数据)
1 | void combine4(vec_ptr v,data_t *dest){ |

k*n循环展开
步长为二,一个循环(21)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17void combine5(vec_ptr v,data_t *dest){
long i;
long length = vec_length(v);
long limit = length-1;
data_t *data=get_vec_start(v);
data_t acc=IDENT;
// combine 2 elements at a time
for(i=0;i<limit;i+=2){
acc=(acc OP data[i])OP data[i+1];
}
// Finish any remaining elements
for(;i<length;i++){
acc = acc OP data[i];
}
*dest=acc;
}
步长为二,两个循环(22)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18void combine6(vec_ptr v,data_t *dest){
long i;
long length = vec_length(v);
long limit = length-1;
data_t *data=get_vec_start(v);
data_t acc0=IDENT;
data_t acc1=IDENT;
// combine 2 elements at a time
for(i=0;i<limit;i+=2){
acc0=(acc0 OP data[i]);
acc1=(acc1 OP data[i+1]);
}
// Finish any remaining elements
for(;i<length;i++){
acc0 = acc0 OP data[i];
}
*dest=acc0 OP acc1;
}
重新结合变换(k*1a)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17void combine7(vec_ptr v,data_t *dest){
long i;
long length = vec_length(v);
long limit = length-1;
data_t *data=get_vec_start(v);
data_t acc=IDENT;
// combine 2 elements at a time
for(i=0;i<limit;i+=2){
acc=acc OP (data[i] OP data[i+1]);
}
// Finish any remaining elements
for(;i<length;i++){
acc = acc OP data[i];
}
*dest=acc;
}
寄存器溢出
现代x86架构拥有16个寄存器,还有16个YMM寄存器可以存储浮点型数,如果需要缓存的变量超过该个数则需要将数据存放到内存,性能可能会下降。
条件控制转移(if…else) VS 条件传送( ? … : … )
条件控制转移指根据代码的条件结果来选择执行的路径,条件传送指先把结果执行,在根据条件结果选择结果值。在相同的情况下,条件传送性能比条件控制转移高。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// CPE 13.5
void minmax1(long a[],long b[],long n){
long i;
for(i=0;i<n;i++){
long t=a[i];
a[i]=b[i];
b[i]=t;
}
}
// CPE 4.0
void minmax2(long a[],long b[],long n){
for(i=0;i<n;i++){
long min=a[i]<b[i]?a[i]:b[i];
long max=a[i]<b[i]?b[i]:a[i];
a[i]=min;
b[i]=max;
}
}