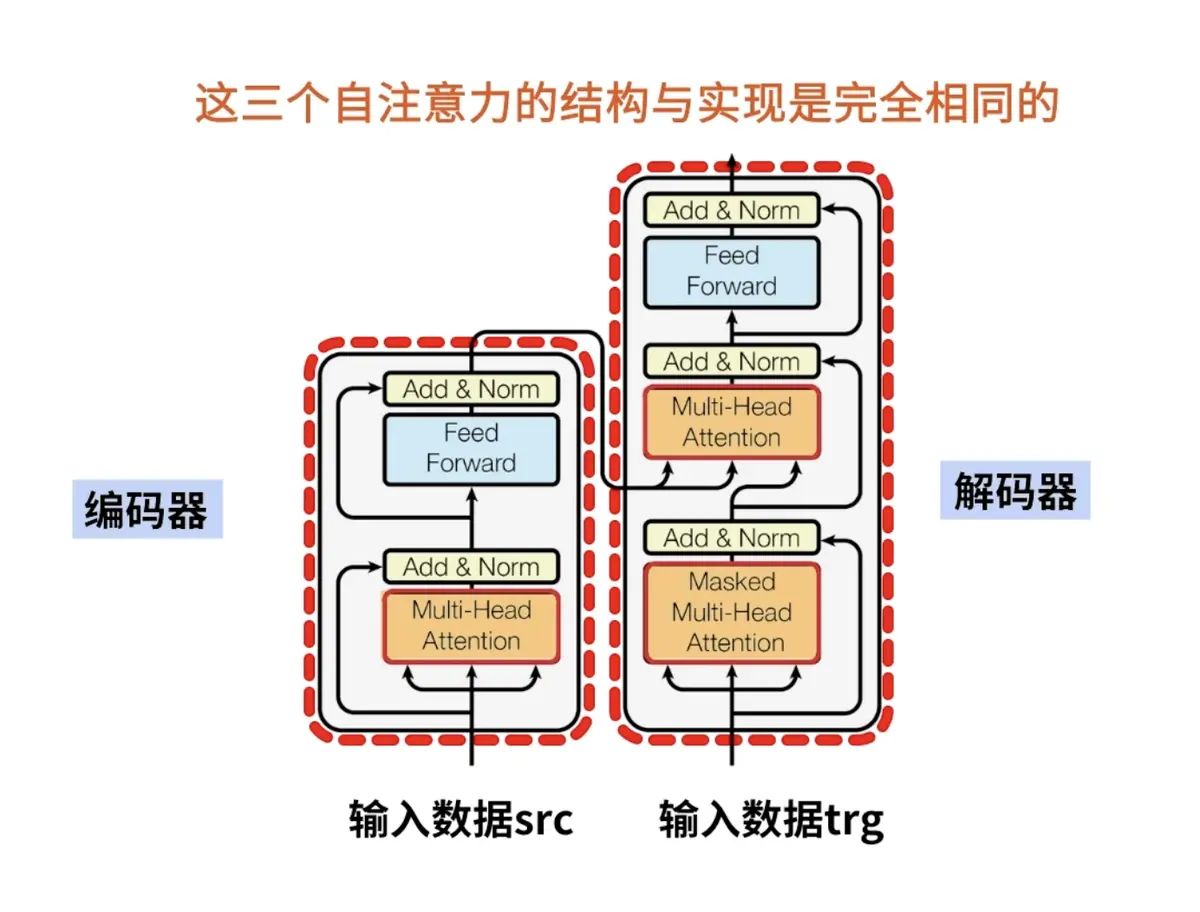
单头注意力
Q(查询query)=> (seq_len×d_k)
K(键值key)=> Q*K 输出每个单词和其他单词的概率关系分布(seq_len x seq_len)
V(值 value)=> 赋予每个向量重要性

d_k:是 Q/K 的维度,通常远小于 d_model(如 d_k=64),目的是降低计算复杂度,将原始得分除以 √d_k,避免因 d_k 过大导致 Softmax 输出过于极端(梯度消失)。
d_model:输入词向量的维度。
输入都是同一个词向量+位置编码,注意力的Q、K、V矩阵参数不同但是长宽相同(seq_len×d_k)
Attention = softmax(Q×K^T / √d_k )*V
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| ┌─────────────────────────────────────────────────────────┐
│ 输入X (seq_len×d_model) │
└───────────┬───────────┬───────────┬───────────────────┘
│ │ │
▼ ▼ ▼
┌───────────┐ ┌───────────┐ ┌───────────┐
│ W_Q │ │ W_K │ │ W_V │
└───────────┘ └───────────┘ └───────────┘
│ │ │
▼ ▼ ▼
┌───────────┐ ┌───────────┐ ┌───────────┐
│ Q │ │ K │ │ V │
└───────────┘ └───────────┘ └───────────┘
│ │ │
└───────────┼───────────┘
│
▼
┌─────────────────────────────────────────┐
│ Q×K^T / √d_k → Softmax → 注意力权重 │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ 注意力权重 × V → 单头输出 │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ 多头拼接 → W_O → 最终输出 │
└─────────────────────────────────────────┘
|
- 单头注意力的输出是融合了上下文信息的 Token 表示矩阵
多头注意力
并行执行多个单头注意力,然后将结果拼接并线性变换,目的是捕捉不同维度的上下文信息。
原先(d_model)的矩阵分解成h个头,每个头都是单头注意力(d_k),但是拼接起来等于d_model
1
2
3
4
5
6
7
8
9
10
11
12
| Q, K, V (seq_len×d_model)
|
├→ 分拆为h个头 → Q1-Qh, K1-Kh, V1-Vh (每个seq_len×d_k)
|
├→ 头1:自注意力 → Output1 (seq_len×d_k)
├→ 头2:自注意力 → Output2 (seq_len×d_k)
├→ ...
├→ 头h:自注意力 → Outputh (seq_len×d_k)
|
├→ 拼接 → Output (seq_len×h*d_k)
|
└→ 线性变换W_O → 最终输出 (seq_len×d_model)
|
掩码自注意力(Masked Self-Attention)
用于 Transformer 的解码器,防止模型看到未来的 Token。
通过在注意力得分矩阵中加入掩码(Mask),将未来 Token 的得分设为 -∞,Softmax 后权重为 0。