基于ANN的FAISS进行毫秒级别召回,然后基于BERT模型精排。
1.评估指标平均精确率(mAP)
只处理 0/1 二元的情况,只考虑topK,不关心topK内部顺序。
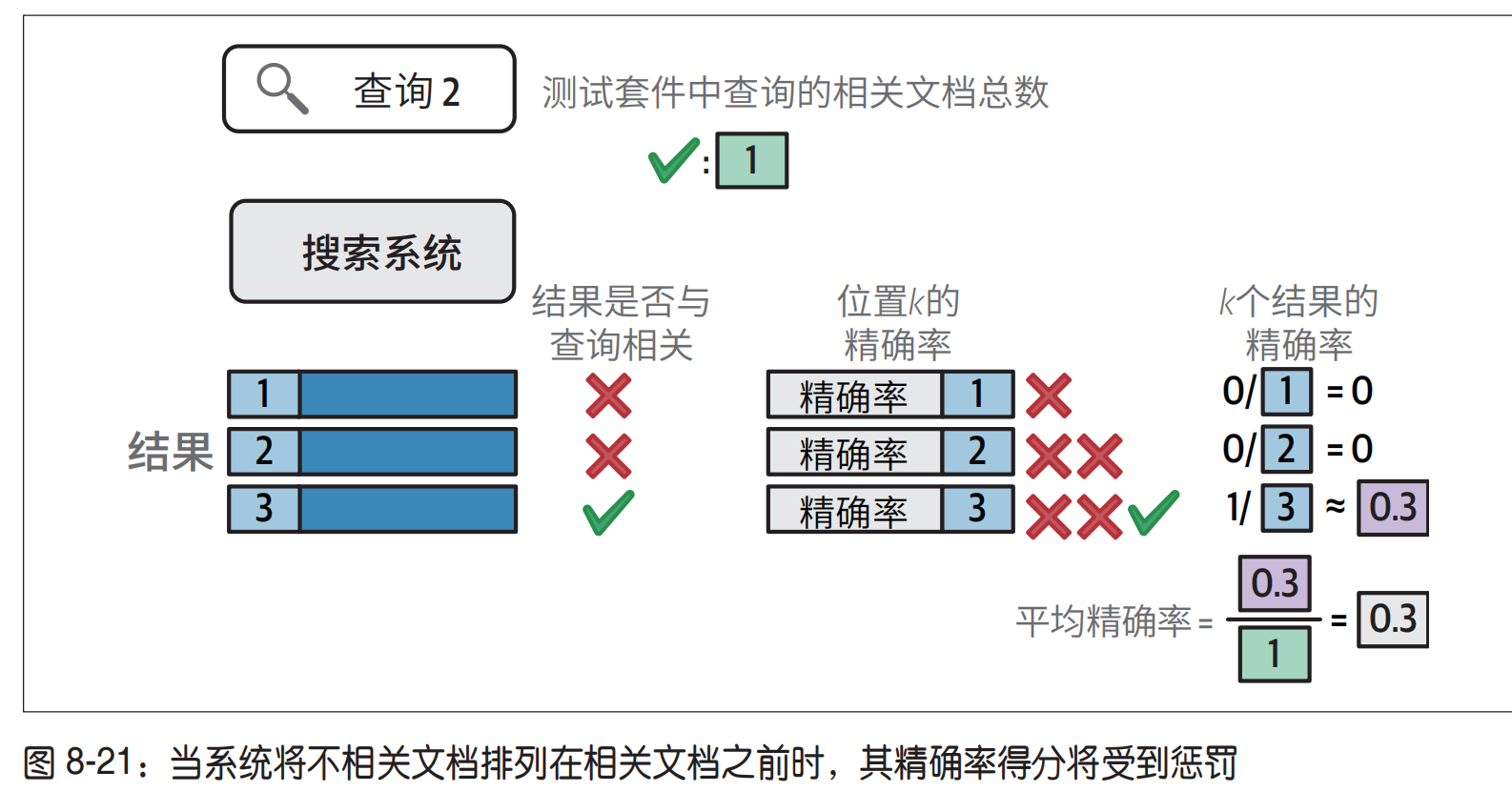
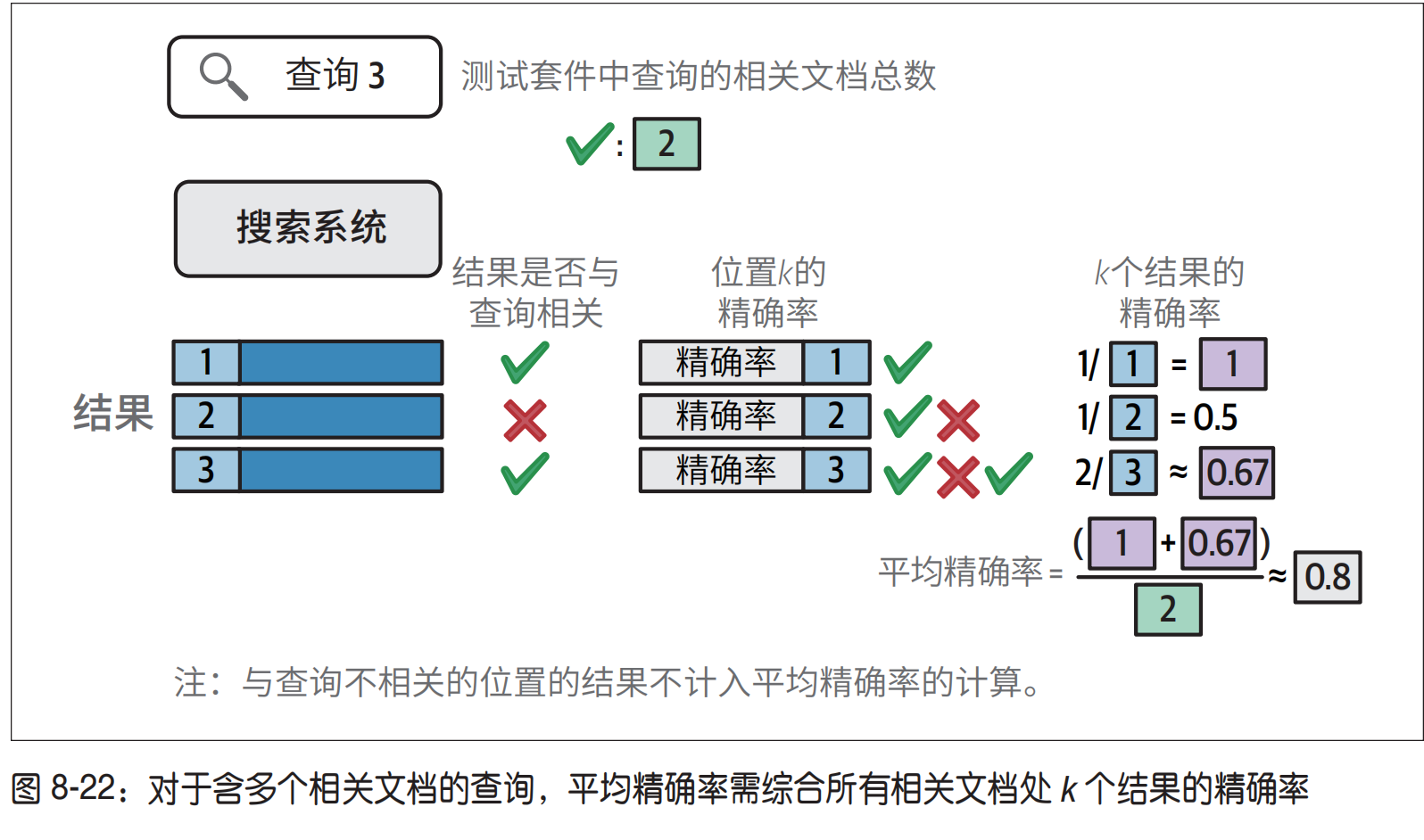
分母:所有相关结果的sum
分子:sum_N N内查询相关个数/N
2.归一化折损累积增益(normalized discounted cumulative gain,nDCG)
能处理 0/1/2/3 多元的情况,关心topK内部顺序。
高关联度的结果排在排名靠前的位置是最合理的,因此:
高关联度的结果对得分的贡献大。
排名越靠前的结果,权重越大。
模型给出的排序结果,是否把 “更相关的东西” 排在了更前面。
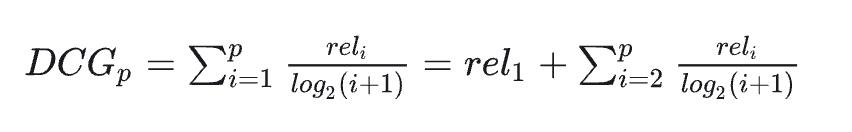
3.AUC 类似AP
衡量预测分数的准确性。ROC曲线是通过将真阳性率(TPR)与假阳性率(FPR)绘制在坐标系中形成的曲线。
4. MRR(Mean Reciprocal Rank)
衡量 “第一个正确答案出现的位置”。
公式:1 /rank_of_first_relevant
对 “首命中” 非常敏感。
适用:问答系统、搜索中 “第一个结果准不准” 很重要的场景。