2PC、TCC、SAGA、本地消息表的原理和优缺点分别是什么?在实际项目中如何选择合适的分布式事务方案?
特性
2PC
TCC
SAGA
本地消息表
一致性
强一致性(ACID)
强一致性(近似 ACID)
最终一致性
最终一致性
业务侵入性
低(依赖数据库)
高(需实现 3 个方法)
中(需实现补偿事务)
低(需加消息表)
性能
低(同步阻塞)
高(无阻塞)
高(无阻塞)
高(异步消息)
实现复杂度
低
高(处理幂等 / 空回滚)
中(协调式易管理)
低
适用事务长度
短事务
短事务
长事务
中短事务
核心问题
同步阻塞、单点故障
业务侵入、实现复杂
补偿逻辑、最终一致
消息延迟、幂等性
SAGA 将分布式事务拆分为一系列本地事务的有序执行链,每个本地事务都有对应的补偿事务:
正向执行
按顺序执行每个本地事务 T1, T2, …, Tn。
反向补偿
如果某个本地事务 Ti 执行失败,按逆序执行补偿事务 Ci-1, Ci-2, …, C1。
TCC(Try-Confirm-Cancel,补偿事务)
TCC 是一种业务侵入式的分布式事务方案,将每个业务操作拆分为三个独立的方法,由业务代码实现:
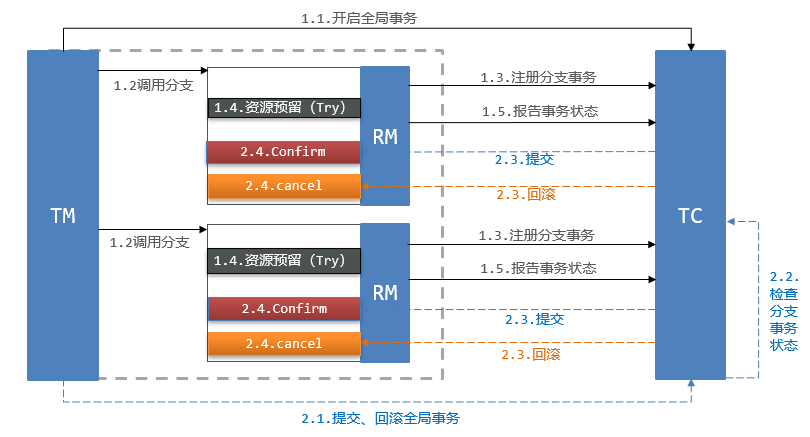
1.Try 阶段
尝试执行业务操作,预留资源(如冻结资金、锁定库存),保证操作的幂等性。
此阶段只做资源检查和预留,不执行最终业务逻辑。
2.Confirm 阶段
确认执行业务操作,使用预留的资源完成最终逻辑。
只有当所有参与者的 Try 阶段都成功时,才会执行 Confirm 阶段。
3.Cancel 阶段
取消执行业务操作,释放预留的资源。
如果任何一个参与者的 Try 阶段失败,会执行所有参与者的 Cancel 阶段。
幂等、空回滚、悬挂?
幂等性就是无论接口调用多少次,返回的结果应该具有一致性。
空回滚(try没执行就cancel):当某分支事务的try阶段阻塞时,可能导致全局事务超时而触发二阶段的cancel操作。在未执行try操作时先执行了cancel操作,这时cancel不能做回滚,就是空回滚。
业务悬挂(cancel之后try):对于已经空回滚的业务,如果以后继续执行try,就永远不可能confirm或cancel
为了实现空回滚、防止业务悬挂,记录冻结金额的同时,记录当前事务id和执行状态1 2 3 4 5 6 7 CREATE TABLE `account_freeze_tbl` ( `xid` varchar(128) NOT NULL COMMENT '事务id', `user_id` varchar(255) DEFAULT NULL COMMENT '用户id', `freeze_money` int(11) unsigned DEFAULT '0' COMMENT '冻结金额', `state` int(1) DEFAULT NULL COMMENT '事务状态,0:try,1:confirm,2:cancel', PRIMARY KEY (`xid`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT;
1.Try业务
记录冻结金额和事务状态0到account_freeze表
扣减account表可用金额
2.Confirm业务
根据xid删除account_freeze表的冻结记录(因为如果一个事务confirm那么记录就没有意义了)
3.Cancel业务
修改account_freeze表,冻结金额为0,state为2
修改account表,恢复可用金额
cancel业务中,根据xid查询account_freeze,如果为null则说明try还没做,需要空回滚
try业务中,根据xid查询account_freeze ,如果存在金额=0/state=2则证明Cancel已经执行,拒绝执行try业务
TCC vs 2PC TCC只需要处理业务异常情况,异常处理相对简单。 2PC适用于对事务一致性要求较高的场景,例如银行转账等,需要保证数据致性和完整性。 而TCC适用于对事务一致性要求不那么高的场景,例如电商库存扣减等,需要保证数据最终一致性即可。
本地消息表 写本地消息+状态,然后链式流转。